bin/kc.[sh|bat] start --cache=ispnConfiguring distributed caches
Configure the caching layer to cluster multiple Keycloak instances and to increase performance.Keycloak is designed for high availability and multi-node clustered setups. The current distributed cache implementation is built on top of Infinispan, a high-performance, distributable in-memory data grid.
Enable distributed caching
When you start Keycloak in production mode, by using the start command, caching is enabled and all Keycloak nodes in your network are discovered.
By default, caches use the jdbc-ping stack which is based upon a TCP transport and uses the configured database to track nodes joining the cluster.
Keycloak allows you to either choose from a set of pre-defined default transport stacks, or to define your own custom stack, as you will see later in this guide.
To explicitly enable distributed infinispan caching, enter this command:
When you start Keycloak in development mode, by using the start-dev command, Keycloak uses only local caches and distributed caches are completely disabled by implicitly setting the --cache=local option.
The local cache mode is intended only for development and testing purposes.
Configuring caches
Keycloak provides a regular Infinispan configuration file located at conf/cache-ispn.xml.
This file contains the default configuration used for the cache-container and JGroups transport.
The following table gives an overview of the specific caches Keycloak uses:
| Cache name | Cache Type | Description |
|---|---|---|
realms |
Local |
Cache persisted realm data |
users |
Local |
Cache persisted user data |
authorization |
Local |
Cache persisted authorization data |
keys |
Local |
Cache external public keys |
crl |
Local |
Cache for X.509 authenticator CRLs |
work |
Replicated |
Propagate invalidation messages across nodes |
authenticationSessions |
Distributed |
Caches authentication sessions, created/destroyed/expired during the authentication process |
sessions |
Distributed |
Cache persisted user session data |
clientSessions |
Distributed |
Cache persisted client session data |
offlineSessions |
Distributed |
Cache persisted offline user session data |
offlineClientSessions |
Distributed |
Cache persisted offline client session data |
loginFailures |
Distributed |
keep track of failed logins, fraud detection |
actionTokens |
Distributed |
Caches action Tokens |
Cache types and defaults
Local caches
Keycloak caches persistent data locally to avoid unnecessary round-trips to the database.
The following data is kept local to each node in the cluster using local caches:
-
realms and related data like clients, roles, and groups.
-
users and related data like granted roles and group memberships.
-
authorization and related data like resources, permissions, and policies.
-
keys
Local caches for realms, users, and authorization are configured to hold up to 10,000 entries per default. The local key cache can hold up to 1,000 entries per default and defaults to expire every one hour. Therefore, keys are forced to be periodically downloaded from external clients or identity providers.
In order to achieve an optimal runtime and avoid additional round-trips to the database you should consider looking at the configuration for each cache to make sure the maximum number of entries is aligned with the size of your database. More entries you can cache, less often the server needs to fetch data from the database. You should evaluate the trade-offs between memory utilization and performance.
Invalidation of local caches
Local caching improves performance, but adds a challenge in multi-node setups.
When one Keycloak node updates data in the shared database, all other nodes need to be aware of it, so they invalidate that data from their caches.
The work cache is a replicated cache and used for sending these invalidation messages. The entries/messages in this cache are very short-lived,
and you should not expect this cache growing in size over time.
Authentication sessions
Authentication sessions are created whenever a user tries to authenticate. They are automatically destroyed once the authentication process completes or due to reaching their expiration time.
The authenticationSessions distributed cache is used to store authentication sessions and any other data associated with it
during the authentication process.
By relying on a distributable cache, authentication sessions are available to any node in the cluster so that users can be redirected to any node without losing their authentication state. However, production-ready deployments should always consider session affinity and favor redirecting users to the node where their sessions were initially created. By doing that, you are going to avoid unnecessary state transfer between nodes and improve CPU, memory, and network utilization.
User sessions
Once the user is authenticated, a user session is created. The user session tracks your active users and their state so that they can seamlessly authenticate to any application without being asked for their credentials again. For each application, the user authenticates with a client session, so that the server can track the applications the user is authenticated with and their state on a per-application basis.
User and client sessions are automatically destroyed whenever the user performs a logout, the client performs a token revocation, or due to reaching their expiration time.
The session data are stored in the database by default and loaded on-demand to the following caches:
-
sessions -
clientSessions
By relying on a distributable cache, cached user and client sessions are available to any node in the cluster so that users can be redirected to any node without the need to load session data from the database. However, production-ready deployments should always consider session affinity and favor redirecting users to the node where their sessions were initially created. By doing that, you are going to avoid unnecessary state transfer between nodes and improve CPU, memory, and network utilization.
These in-memory caches for user sessions and client sessions are limited to, by default, 10000 entries per node which reduces the overall memory usage of Keycloak for larger installations. The internal caches will run with only a single owner for each cache entry.
Offline user sessions
As an OpenID Connect Provider, the server is capable of authenticating users and issuing offline tokens. When issuing an offline token after successful authentication, the server creates an offline user session and offline client session.
The following caches are used to store offline sessions:
-
offlineSessions
-
offlineClientSessions
Like the user and client sessions caches, the offline user and client session caches are limited to 10000 entries per node by default. Items which are evicted from the memory will be loaded on-demand from the database when needed.
Password brute force detection
The loginFailures distributed cache is used to track data about failed login attempts.
This cache is needed for the Brute Force Protection feature to work in a multi-node Keycloak setup.
Action tokens
Action tokens are used for scenarios when a user needs to confirm an action asynchronously, for example in the emails sent by the forgot password flow.
The actionTokens distributed cache is used to track metadata about action tokens.
You can see the applied Infinispan configuration in the logs by configuring --log-level=info,org.keycloak.connections.infinispan.DefaultInfinispanConnectionProviderFactory:debug.
|
Volatile user sessions
By default, regular user sessions are stored in the database and loaded on-demand to the cache. It is possible to configure Keycloak to store regular user sessions in the cache only and minimize calls to the database.
Since all the sessions in this setup are stored in-memory, there are two side effects related to this:
-
Losing sessions when all Keycloak nodes restart.
-
Increased memory consumption.
When using volatile user sessions, the cache is the source of truth for user and client sessions. Keycloak automatically adjusts the number of entries that can be stored in memory, and increases the number of copies to prevent data loss.
Follow these steps to enable this setup:
-
Disable
persistent-user-sessionsfeature using the following command:bin/kc.sh start --features-disabled=persistent-user-sessions ...
|
Disabling |
Configuring cache maximum size
In order to reduce memory usage, it’s possible to place an upper bound on the number of entries which are stored in a given
cache. To specify an upper bound of on a cache, you must provide the following command line argument
--cache-embedded-${CACHE_NAME}-max-count=, with ${CACHE_NAME} replaced with the name of the cache you would like to
apply the upper bound to. For example, to apply an upper-bound of 1000 to the offlineSessions cache you would configure
--cache-embedded-offline-sessions-max-count=1000. An upper bound can not be defined on the following caches:
actionToken, authenticationSessions, loginFailures, work.
Setting a maximum cache size for sessions, clientSessions is not supported when volatile sessions are enabled.
Specify your own cache configuration file
To specify your own cache configuration file, enter this command:
bin/kc.[sh|bat] start --cache-config-file=my-cache-file.xmlThe configuration file can be an absolute path or path relative to the conf/ directory.
Modifying cache configuration defaults
Keycloak automatically creates all required caches with the expected configurations. You can add additional caches or override the default cache configurations in conf/cache-ispn.xml or in your own file provided via --cache-config-file.
To see the applied Infinispan configuration in the logs, configure --log-level=info,org.keycloak.connections.infinispan.DefaultInfinispanConnectionProviderFactory:debug.
|
While overriding the default cache configurations via XML is technically possible, it is not supported.
This is only recommended for advanced use-cases where the default cache configurations are proven to be problematic.
The only supported way to change the default cache configurations is via the |
In order to prevent a warning being logged when a modified default cache configuration is detected, add the following option:
bin/kc.[sh|bat] start --cache-config-mutate=trueCLI options for remote server
For configuration of Keycloak server for high availability and multi-node clustered setup there was introduced following CLI options cache-remote-host, cache-remote-port, cache-remote-username and cache-remote-password simplifying configuration within the XML file.
Once any of the declared CLI parameters are present, it is expected there is no configuration related to remote store present in the XML file.
Connecting to an insecure Infinispan server
| Disabling security is not recommended in production! |
In a development or test environment, it is easier to start an unsecured Infinispan server.
For these use case, the CLI options cache-remote-tls-enabled disables the encryption (TLS) between Keycloak and Infinispan.
Keycloak will fail to start if the Infinispan server is configured to accept only encrypted connections.
The CLI options cache-remote-username and cache-remote-password are optional and, if not set, Keycloak will connect to the Infinispan server without presenting any credentials.
If the Infinispan server has authentication enabled, Keycloak will fail to start.
Topology aware data distribution
Configuring Keycloak to be aware of your network topology, increases data availability in the presence of hardware failures, as Infinispan is able to ensure that data is distributed correctly.
For example, if num_owners=2 is configured for a cache, it will ensure that the two owners are not stored on the same node when possible.
|
By default, user and client sessions are safely stored in the database, and they are not affected by these settings. The remaining distributed caches are affected by this configuration. |
The following topology information is available to configure:
- Site name
-
If your Keycloak cluster is deployed between different datacenters, use this option to ensure the data replicas are stored in a different datacenter. It prevents data loss if a datacenter goes offline or fails.
Use the SPI option
spi-cache-embedded--default--site-name(or environment variableKC_SPI_CACHE_EMBEDDED__DEFAULT__SITE_NAME). The value itself is not important, but each datacenter must have a unique value.For example:
--spi-cache-embedded--default--site-name=site-1 - Rack name
-
If your Keycloak cluster is running in different racks on your datacenter, set this option to ensure the data replicas are stored in a different physical rack. It prevents data loss if a rack is suddenly disconnected or fails.
Use the SPI option
spi-cache-embedded--default--rack-name(or environment variableKC_SPI_CACHE_EMBEDDED__DEFAULT__RACK_NAME). The value itself is not important, but each rack must have a unique value.For example:
--spi-cache-embedded--default--rack-name=rack-1 - Machine name
-
If you have multiple Keycloak instances running on the same physical machine (using virtual machines or containers for example), use this option to ensure the data replicas are stored in different physical machines. It prevents data loss against a physical machine failure.
Use the SPI option
spi-cache-embedded--default--machine-name(or environment variableKC_SPI_CACHE_EMBEDDED__DEFAULT__MACHINE_NAME). The value itself is not important, but each machine must have a unique value.For example:
--spi-cache-embedded--default--machine-name=machine-1The Keycloak Operator automatically configure the machine name based on the Kubernetes node. It ensures that if multiple pods are scheduled on the same node, data replicas are still replicated across distinct nodes when possible. We recommend to set up anti-affinity rules and/or topology spread constraints to prevent multiple Pods from being scheduled on the same node, further reducing the risk of a single node failure causing data loss.
Transport stacks
Transport stacks ensure that Keycloak nodes in a cluster communicate in a reliable fashion. Keycloak supports a wide range of transport stacks:
-
jdbc-ping -
kubernetes(deprecated) -
jdbc-ping-udp(deprecated) -
tcp(deprecated) -
udp(deprecated) -
ec2(deprecated) -
azure(deprecated) -
google(deprecated)
To apply a specific cache stack, enter this command:
bin/kc.[sh|bat] start --cache-stack=<stack>The default stack is set to jdbc-ping when distributed caches are enabled, which is backwards compatible with the defaults in the 26.x release stream of Keycloak.
Available transport stacks
The following table shows transport stacks that are available without any further configuration than using the --cache-stack runtime option:
| Stack name | Transport protocol | Discovery |
|---|---|---|
|
TCP |
Database registry using the JGroups |
|
UDP |
Database registry using the JGroups |
The following table shows transport stacks that are available using the --cache-stack runtime option and a minimum configuration:
| Stack name | Transport protocol | Discovery |
|---|---|---|
|
TCP |
DNS resolution using the JGroups |
|
TCP |
IP multicast using the JGroups |
|
UDP |
IP multicast using the JGroups |
When using the tcp, udp or jdbc-ping-udp stack, each cluster must use a different multicast address and/or port so that their nodes form distinct clusters.
By default, Keycloak uses 239.6.7.8 as multicast address for jgroups.mcast_addr and 46655 for the multicast port jgroups.mcast_port.
Use -D<property>=<value> to pass the properties via the JAVA_OPTS_APPEND environment variable or in the CLI command.
|
Additional Stacks
It is recommended to use one of the stacks available above. Additional stacks are provided by Infinispan, but it is outside the scope of this guide how to configure them. Please refer to Setting up Infinispan cluster transport and Customizing JGroups stacks for further documentation.
Securing transport stacks
Encryption using TLS is enabled by default for TCP-based transport stacks, which is also the default configuration. No additional CLI options or modifications of the cache XML are required as long as you are using a TCP-based transport stack.
|
If you are using a transport stack based on
|
With TLS enabled, Keycloak auto-generates a self-signed RSA 2048 bit certificate to secure the connection and uses TLS 1.3 to secure the communication.
The keys and the certificate are stored in the database so they are available to all nodes.
By default, the certificate is valid for 60 days and is rotated at runtime every 30 days.
Use the option cache-embedded-mtls-rotation-interval-days to change this.
Running inside a service mesh
When using a service mesh like Istio, you might need to allow a direct mTLS communication between the Keycloak Pods to allow for the mutual authentication to work.
Otherwise, you might see error messages like JGRP000006: failed accepting connection from peer SSLSocket that indicate that a wrong certificate was presented, and the cluster will not form correctly.
You then have the option to allow direct mTLS communication between the Keycloak Pods, or rely on the service mesh transport security to encrypt the communication and to authenticate peers.
To allow direct mTLS communication for Keycloak when using Istio:
-
Apply the following configuration to allow direct communication.
apiVersion: security.istio.io/v1beta1 kind: PeerAuthentication metadata: name: infinispan-allow-nomtls spec: selector: matchLabels: app: keycloak (1) portLevelMtls: "7800": (2) mode: PERMISSIVE1 Update the labels to match your Keycloak deployment. 2 Port 7800 is the default. Adjust it if you change the data transmission port.
As an alternative, to disable the mTLS communication, and rely on the service mesh to encrypt the traffic:
-
Set the option
cache-embedded-mtls-enabledtofalse. -
Configure your service mesh to authorize only traffic from other Keycloak Pods for the data transmission port (default: 7800).
Providing your own keys and certificates
Although not recommended for standard setups, if it is essential in a specific setup, you can configure the keystore with the certificate for the transport stack manually. cache-embedded-mtls-key-store-file sets the path to the keystore, and cache-embedded-mtls-key-store-password sets the password to decrypt it.
The truststore contains the valid certificates to accept connection from, and it can be configured with cache-embedded-mtls-trust-store-file (path to the truststore), and cache-embedded-mtls-trust-store-password (password to decrypt it).
To restrict unauthorized access, always use a self-signed certificate for each Keycloak deployment.
Network Ports
To ensure a healthy Keycloak clustering, some network ports need to be open.
The table below shows the TCP ports that need to be open for the jdbc-ping stack, and a description of the traffic that goes through it.
| Port | Option | Property | Description |
|---|---|---|---|
|
|
|
Unicast data transmission. |
|
|
Failure detection by protocol |
If an option is not available for the port you require, configure it using a system property -D<property>=<value>
in your JAVA_OPTS_APPEND environment variable or in your CLI command.
|
Network bind address
To ensure a healthy Keycloak clustering, the network port must be bound on an interface that is accessible from all other nodes of the cluster.
By default, it picks a site local (non-routable) IP address, for example, from the 192.168.0.0/16 or 10.0.0.0/8 address range.
To override the address, set the option cache-embedded-network-bind-address=<IP>.
The following special values are also recognized:
| Value | Description |
|---|---|
|
Picks a global IP address if available.
If not available, it falls back to |
|
Picks a site-local (non-routable) IP address (for example, from the 192.168.0.0 or 10.0.0.0 address ranges). This is the default value. |
|
Picks a link-local IP address from 169.254.1.0 through 169.254.254.255. |
|
Picks any non-loopback address. |
|
Picks a loopback address (for example, 127.0.0.1). |
|
Picks an address that matches a pattern against the interface name.
For example, |
|
Picks an address that matches a pattern against the host address.
For example, |
|
Picks an address that matches a pattern against the host name.
For example, |
To set up for IPv6 only and have Keycloak pick the bind address automatically, use the following settings:
export JAVA_OPTS_APPEND="-Djava.net.preferIPv4Stack=false -Djava.net.preferIPv6Addresses=true"For more details about JGroups transport, check the JGroups documentation page or the Infinispan documentation page.
Running instances on different networks
If you run Keycloak instances on different networks, for example behind firewalls or in containers, the different instances will not be able to reach each other by their local IP address. In such a case, set up a port forwarding rule (sometimes called “virtual server”) to their local IP address.
When using port forwarding, use the following options so each node correctly advertises its external address to the other nodes:
| Option | Description |
|---|---|
|
Port that other instances in the Keycloak cluster should use to contact this node. |
|
IP address that other instances in the Keycloak should use to contact this node. |
Verify cluster and network health
This section provides methods to verify that your Keycloak cluster has formed correctly and that network communication between instances is functioning as expected. It is crucial to perform these checks after deployment to ensure high availability and data consistency.
To verify if the cluster is formed properly, check one of these locations:
-
Admin UI
Access the Keycloak Web UI, typically available at
https://<your-host>/admin/master/console/#/master/providers. Under the Provider Info section, locate the connectionsInfinispan entry. Click on Show more to expand its details. You should find information about the cluster status and the health of individual caches.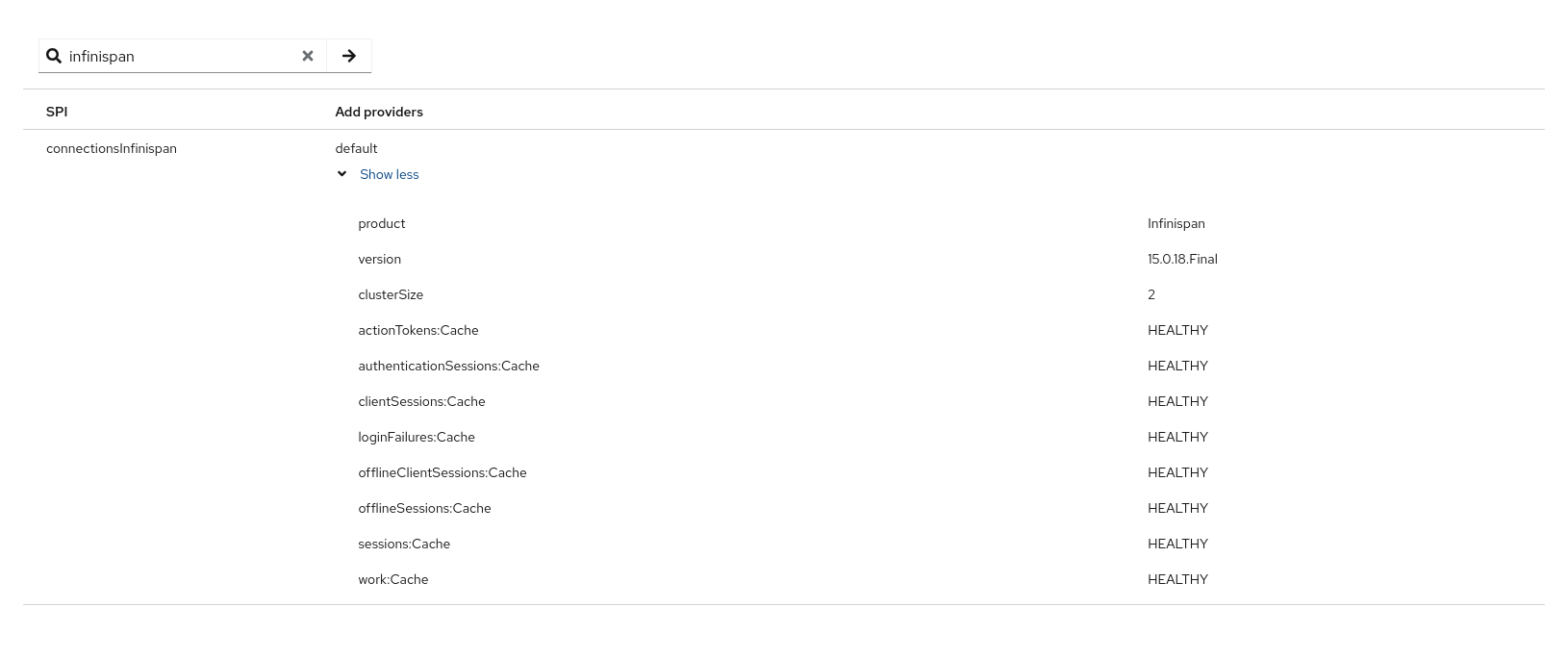
-
Logs
Infinispan logs a cluster view every time a new instance joins or leaves the cluster. Search for log entries with the ID
ISPN000094.A healthy cluster view will show all expected nodes. For example:
ISPN000094: Received new cluster view for channel ISPN: [node1-26186|1] (2) [node1-26186, node2-37007]This log entry indicates that the cluster named "ISPN" currently has 2 nodes:
node1-26186andnode2-37007. The(2)confirms the total number of nodes in the cluster. -
Metrics
Keycloak exposes Infinispan metrics via a Prometheus endpoint, which can be visualized in tools like Grafana. The metric
vendor_cluster_sizeshows the current number of instances in the cluster. You should verify that this metric matches the expected number of running instances configured in your cluster.Refer to Clustering metrics for more information.
Exposing metrics from caches
Metrics from caches are automatically exposed when the metrics are enabled.
To enable histograms for the cache metrics, set cache-metrics-histograms-enabled to true.
While these metrics provide more insights into the latency distribution, collecting them might have a performance impact, so you should be cautious to activate them in an already saturated system.
bin/kc.[sh|bat] start --metrics-enabled=true --cache-metrics-histograms-enabled=trueFor more details about how to enable metrics, see Gaining insights with metrics.
Relevant options
| Type or Values | Default | |
|---|---|---|
|
|
|
|
File |
|
|
|
|
Available only when metrics are enabled |
|
|
Available only when 'cache' type is set to 'ispn' Use 'jdbc-ping' instead by leaving it unset
Deprecated values: |
|
Embedded Cache
| Type or Values | Default | |
|---|---|---|
|
Integer |
|
Available only when embedded Infinispan clusters configured |
Integer |
|
|
Integer |
|
|
Integer |
|
Available only when a TCP based cache-stack is used |
|
|
Available only when property 'cache-embedded-mtls-enabled' is enabled |
String |
|
Available only when property 'cache-embedded-mtls-enabled' is enabled |
String |
|
Available only when property 'cache-embedded-mtls-enabled' is enabled |
Integer |
|
Available only when property 'cache-embedded-mtls-enabled' is enabled |
String |
|
Available only when property 'cache-embedded-mtls-enabled' is enabled |
String |
|
Available only when Infinispan clustered embedded is enabled |
String |
|
Available only when Infinispan clustered embedded is enabled |
Integer |
|
Available only when Infinispan clustered embedded is enabled |
String |
|
Available only when Infinispan clustered embedded is enabled |
Integer |
|
Available only when embedded Infinispan clusters configured |
Integer |
|
Available only when embedded Infinispan clusters configured |
Integer |
|
|
Integer |
|
Available only when embedded Infinispan clusters configured |
Integer |
|
|
Integer |
On this page